실시간 개인화 추천은? 카우치베이스 + AI 에이전트 아키텍처

"휴가 어디 갈래?"
대충 "바다 보고 싶어" 한 마디 던졌더니, AI 에이전트가 30분 만에 완벽한 계획서를 들고 왔다면?
“한님 맞춤 여름휴가 플랜 v2.1
🏖️ 제주 함덕해수욕장 (한적한 동쪽 해변, 한님 취향저격)
✈️ 김포-제주 8/17 14:30 출발편 예약완료 (창가석)
🍽️ 현지 맛집 3곳 + 예약시간까지 최적화
PS: 작년에 부산 해운대 가셨을 때 "사람 너무 많다"고 하셔서 이번엔 한적한 곳으로 골랐어요!”
이정도면... 비서 월급 줘야…ㅋㅋ 근데 이게 상상이 아니라 이미 현실이 되고 있다. 그리고 이런 AI 에이전트 뒤에는 아주 똑똑한 개인화 엔진이 돌아가고 있다는 사실.
AI 에이전트 개인화 = 새로운 골드러시
솔직히 말하면, 지금 AI 에이전트 개인화 시장은 2007년 iPhone 출시 직후와 비슷한 느낌이다. "이게 정말 될까?" 하던 사람들이 1년 후에는 "이거 없으면 어떻게 살았지?" 하게 되는 그런 변곡점.
개인적으로 완전 bullish한 이유가 몇 개 있는데...
첫 번째: 데이터는 이미 충분하다
우리가 스마트폰에 남기는 디지털 기록만 봐도:
- 카카오톡 대화 패턴 (언어 선호도, 감정 상태)
- 유튜브 시청 기록 (관심사, 라이프스타일)
- 배달앱 주문 내역 (식성, 예산대, 생활패턴)
- 카드 결제 내역 (소비 성향, 동선)
- 구글 검색어 (고민거리, 니즈)
이 정도면 나보다 AI가 나를 더 잘 아는 수준. 무서운 얘기지만 현실이다.
두 번째: 기술적 완성도가 급격히 올라가고 있다
2023년까지만 해도 "AI가 추천해준 맛집이 문 닫았네" 같은 일이 허다했는데, 이제는 실시간 데이터 연동이 가능해졌다. RAG(Retrieval-Augmented Generation) 덕분에 최신 정보를 즉시 반영할 수 있게 된 것.
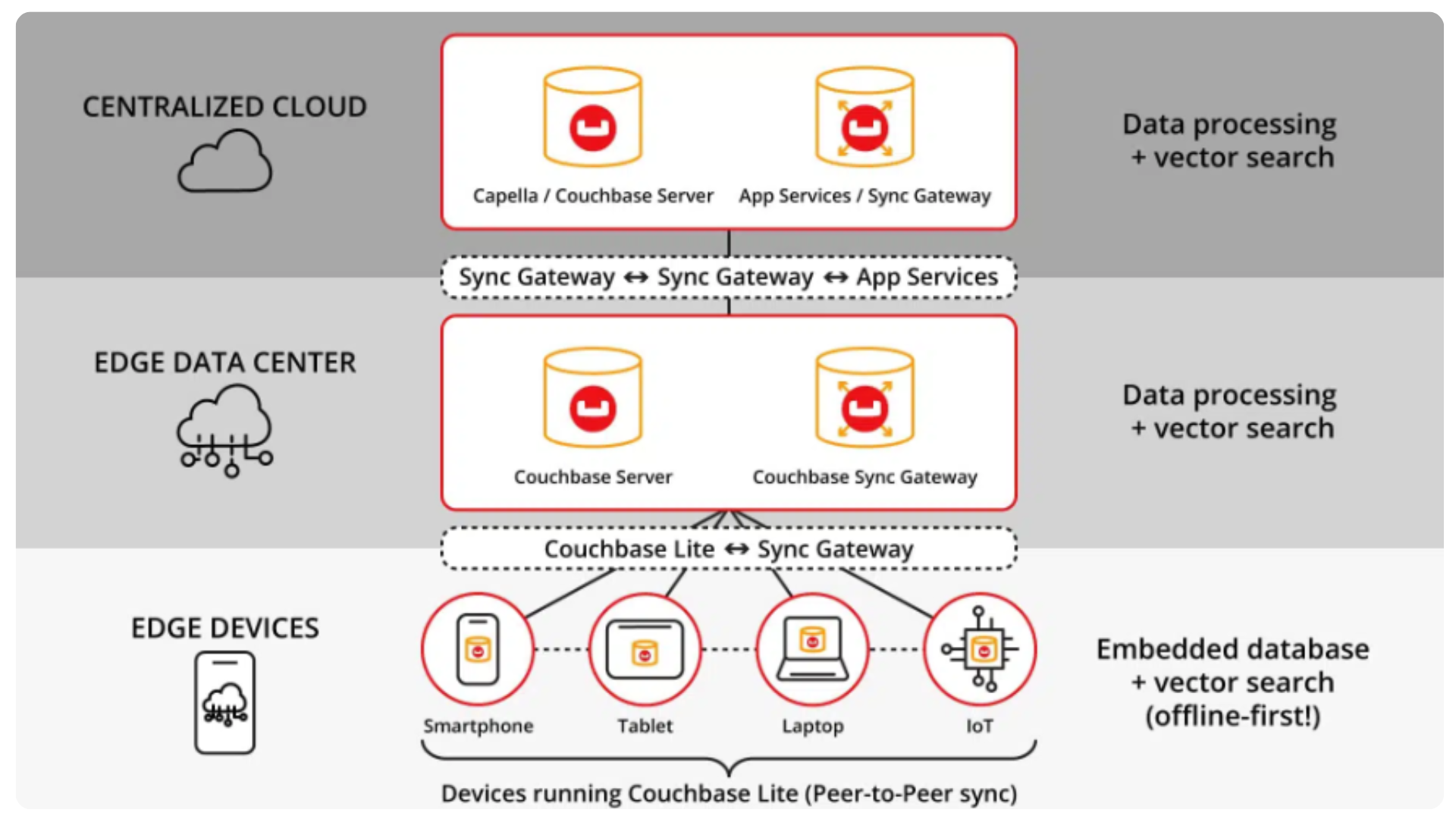
더 중요한 건, 벡터 검색 기술이 모바일에서도 돌아간다는 점. 개인정보를 클라우드로 보내지 않고도 디바이스에서 직접 개인화 추천이 가능해진 거다.
세 번째: 경제적 가치가 명확하다
기존 추천 시스템은 "이런 상품 어때요?" 수준이었다면, AI 에이전트는 "이거 지금 사면 내일까지 배송되고, 당신 예산에 맞고, 기존에 산 것과 잘 어울려요" 수준.
단순 노출이 아니라 액션으로 이어지는 추천이니까 전환율이 몇 배로 뛸 수밖에 없다. 이커머스 입장에서는 광고비를 10분의 1로 줄이면서도 매출은 2배로 늘릴 수 있는 마법 같은 기술.
근데 왜 다들 못 만들고 있을까?
진짜 문제는 기술이 아니라 아키텍처에 있다.
AI 에이전트가 진짜 똑똑해지려면:
- 실시간성: 사용자가 "배고파"라고 말하는 순간, 현재 위치 기준 5분 내 배달 가능한 맛집을 찾아야 함
- 개인화: 과거 주문 내역, 알러지 정보, 예산대, 오늘 기분까지 고려해야 함
- 컨텍스트 유지: "아까 말한 그 레스토랑"이라고 하면 30분 전 대화 내용을 기억해야 함
- 멀티모달: 텍스트뿐만 아니라 이미지, 위치, 시간 등 모든 입력을 종합 판단해야 함
이걸 기존 아키텍처로 구현하려면?
PostgreSQL에서 사용자 프로필 관리하고, Redis로 세션 관리하고, Elasticsearch에서 벡터 검색하고, MongoDB에 대화 로그 저장하고... 무한반복이다.
각각 따로 관리하고, 데이터 동기화하고, 장애 나면 어디서 터졌는지 찾느라 밤새는 그런 지옥이다...이때 등장하는 게 카우치베이스
카우치베이스가 AI 에이전트에 최적화된 이유
JSON 네이티브 = 개인화 데이터의 자연스러운 형태
AI 에이전트가 다루는 개인화 데이터는 생각보다 복잡하다. 사용자 한 명당 음식 취향(한식, 일식 좋아하고 해산물 알러지), 여행 패턴(호텔 선호, 비행기 > 버스, 해변이나 하이킹 좋아함), 행동 성향(오전 9시-밤 11시 활동, 빠른 결정형, 가격 민감도 70%) 같은 수십 가지 속성이 들어간다.
여기에 대화 기록까지 더하면? "8월 1일 오후 2시 30분에 여행 계획 상담했고, 여름휴가 컨텍스트에서 조용한 해변 언급했다"는 식의 시간별 상호작용 데이터까지.
이런 비정형 데이터를 관계형 DB에 우겨넣으려면... 테이블이 수십 개가 나올 것 같다. 그리고 사용자마다 선호도 항목이 다르면? 스키마 지옥이 펼쳐진다.
카우치베이스는 JSON을 네이티브로 지원하니까, 이런 복잡한 개인화 데이터도 그냥 저장하고 바로 쿼리할 수 있다.
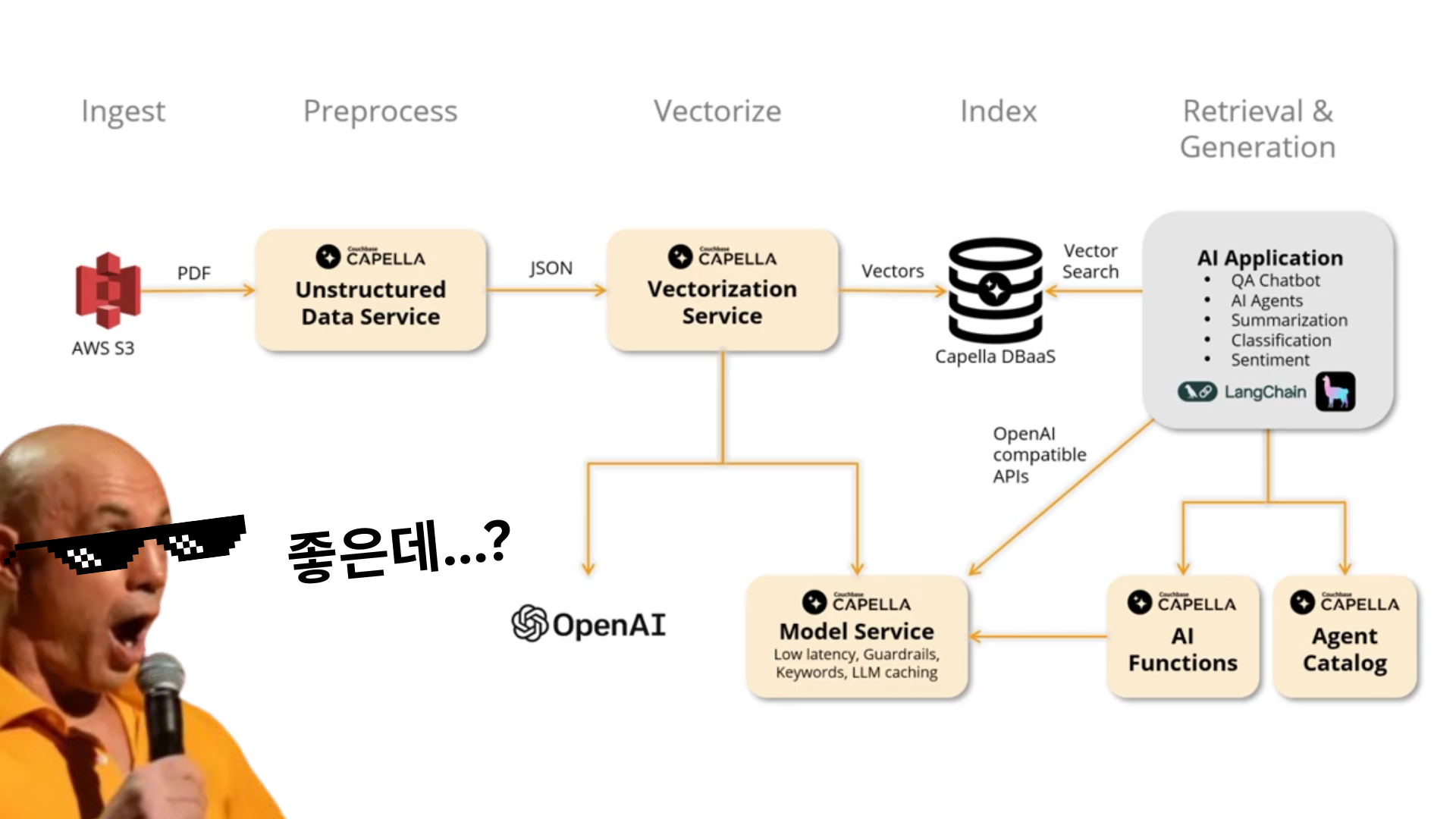
벡터 검색 + 전통적 쿼리의 결합
AI 에이전트가 "한적한 해변"이라는 요청을 받으면:
- 벡터 검색: "한적한 해변"과 의미적으로 유사한 장소들을 찾아냄
- 전통적 쿼리: 사용자 예산, 날짜, 위치 조건으로 필터링
- 개인화 스코어링: 과거 여행 패턴과 만족도 데이터로 점수 계산
이 모든 과정이 한 번의 쿼리로 끝난다. Couchbase Vector Search의 진짜 매력이 여기에 있다.
여행지 테이블에서 "한적한 해변" 벡터 검색하면서 동시에 사용자 예산대, 여행 날짜로 필터링하고, 과거 여행 만족도까지 고려해서 개인화 점수를 매기는 게 하나의 NoSQL로 처리된다는 것.
실시간 성능 = 자연스러운 대화의 핵심
AI 에이전트와 대화할 때 "잠시만요, 찾고 있어요..."라는 메시지가 20초 이상 뜨면? 사용자는 바로 창을 닫는다.
카우치베이스의 메모리 우선 아키텍처는 개인화 쿼리를 밀리초 단위로 처리한다. 사용자가 질문을 끝내기도 전에 관련 옵션들을 미리 준비해두는 수준.
특히 대화 컨텍스트를 실시간으로 업데이트하면서도 성능이 떨어지지 않는다는 게 핵심.
사용자가 "여름휴가 계획 중, 조용한 해변 찾고 있고, 예산 20만원 이하"라는 컨텍스트에서 대화하다가 갑자기 "아, 그런데 숙소는 호텔로 했으면 좋겠어"라고 추가 정보를 주면? 기존 컨텍스트에 실시간으로 "숙소 타입: 호텔 선호"가 추가되면서 추천 결과가 즉시 업데이트된다.
개발팀이 주의할 점들
프라이버시 vs 개인화의 균형
개인화가 정교해질수록 더 많은 개인정보가 필요하다. 하지만 사용자들은 점점 더 프라이버시에 민감해지고 있고.
해결책: Couchbase Mobile을 활용한 온디바이스 개인화
민감한 개인정보는 디바이스에서만 처리하고, 익명화된 패턴 데이터만 클라우드로 전송한다. 개인화 모델도 디바이스에서 직접 실행해서 개인정보가 외부로 나가지 않도록 한다.
사용자 프로필 정보를 디바이스 로컬 데이터베이스에서 가져와서, 벡터 검색까지 모두 디바이스에서 처리하는 식이다. 클라우드로는 "20대 남성이 해변 여행을 선호한다"는 정도의 통계 정보만 보낸다.
실시간성 vs 정확성의 트레이드오프
너무 빠른 추천은 부정확할 수 있고, 너무 정확한 추천은 느릴 수 있다.
해결책: 다층 캐싱 전략
1차: 즉시 응답용 캐시된 일반적 추천을 바로 보여준다. "잠시만요" 메시지 없이 일단 뭔가는 보여주는 것.
2차: 백그라운드에서 사용자 맞춤 개인화 추천을 계산한다. 사용자 프로필, 대화 컨텍스트, 쿼리 내용을 종합해서 정교한 추천을 만드는 과정.
3차: 사용자가 추천 결과에 어떻게 반응하는지(클릭, 좋아요, 건너뛰기 등) 보면서 실시간으로 추천을 최적화한다.
결과적으로 사용자는 즉시 뭔가를 보면서, 점점 더 정확해지는 추천을 경험하게 된다...!
AI 에이전트는 이제 시작
AI 에이전트 개인화는 선택이 아니라 필수가 되고 있다.
아마존이 추천 시스템으로 매출의 35%를 올리고, 넷플릭스가 개인화로 연간 10억 달러를 절약하는 걸 보면, 이미 답은 나와 있다.
문제는 "할까 말까"가 아니라 "어떻게 잘할까"다.
그리고 그 해답은 적절한 아키텍처 선택에서 시작된다. 복잡한 시스템을 여러 개 연결해서 "일단 돌아가게" 만들 수도 있지만, 처음부터 AI 에이전트를 염두에 둔 설계를 한다면?
6개월 후에 "아, 처음부터 제대로 했으면..." 하는 후회는 안 하게 될 것 같다.
AI 에이전트가 나보다 나를 더 잘 아는 세상.
무섭기도 하지만, 잘 만들면 정말 편할 것 같다. 여러분은 어떻게 생각하시나요?
AI 에이전트를 만들고 있다면 같이 이야기 나눠봐요!



