ChatGPT 한국어 서비스, Couchbase로 만든다면?

아무리 시도해도 비슷한 답변만 나온다면 그때 속으로 "아, 한국어 잘 알아듣는 AI 서비스 좀 누가 만들어줘..."라고 생각해본 적 있을듯.
혹시 OpenAI가 진짜로 오로지 한국 시장을 위한 제품을 만들면?
아니면 네이버나 카카오가 "한국형 ChatGPT"를 만든다면 어떤 기술 스택을 써야 할까.
MongoDB 쓰면서 "왜 이래?" 하다가, Redis 따로 붙이고, Elasticsearch 또 붙이고... 그러다 새벽 3시에 눈쓰고…
Couchbase라면 한 방에 해결할 수 있을 것 같은데... 한번 상상해보자.
1. RAG 구현의 진짜 현실: "검색이 느리면 AI도 바보가 된다"
ChatGPT 같은 LLM 서비스의 핵심은 RAG(Retrieval-Augmented Generation)다. 사용자가 질문하면 관련 문서를 빠르게 찾아서 LLM에게 컨텍스트로 제공하는 것. 문제는 이 "빠르게 찾기"가 생각보다 까다롭다는 점.
기존 방식의 한계들
대부분의 팀이 이렇게 시작할듯:
- PostgreSQL에 텍스트 저장
- Pinecone 또는 Weaviate에 벡터 저장
- Redis로 자주 쓰는 응답 캐싱
- Elasticsearch로 키워드 검색
그런데 이렇게 하면... 사용자가 "삼성전자 주가 전망 어때?" 물어본다고 가정하면:
- 벡터 DB에서 관련 문서 검색 → 200ms
- PostgreSQL에서 실제 텍스트 가져오기 → 100ms
- Redis에서 캐시 확인 → 50ms
- 전체 컨텍스트 조합해서 AI API 호출 → 2초
총 2.35초…? 성격 급한 한국 유저라면 "아 답답해" 소리 나올 만하다.
Couchbase라면?
Couchbase의 Vector Search는 문서 DB와 벡터 검색이 하나로 통합되어 있다.
벡터 검색과 실제 문서 조회가 한 번의 쿼리로 끝. 별도 시스템 간 통신 없이 빠르게 완료.
더 중요한 건, JSON 네이티브라서 문서 구조가 복잡해져도 스키마 변경 부담이 적다는 점. "오늘은 뉴스 기사, 내일은 논문, 모레는 유튜브 자막" 이런 식으로 데이터 형태가 계속 바뀌는 AI 서비스에서는 이런 유연성이 금값이다.
실제 성능 차이:
기존 분산 스택(여러 시스템 왕복) 평균 2~3초
→ Couchbase 최적화 후 100ms 단위로 빠르게 답변 가능.
“AI 느려서 짜증" → "어? 이거 진짜 빠르네!" 변화의 순간을 맛볼 수 있다.
2. 한국어 특화와 컨텍스트 저장: "한글이 어려워서 AI가 헤맸다고?"
한국어 AI 서비스의 진짜 어려움은 언어 특성에 있다. 조사, 어미 변화, 높임법, 줄임말... "ㅇㅇ 그거 어케 해?"라는 질문도 이해해야 한다.
한국어 임베딩의 복잡함
예를 들어 사용자가 "삼성전자"를 검색할 때:
"삼성전자는", "삼성전자가", "삼성전자를"
"삼전", "삼성", "갤럭시 만드는 회사", "스마트폰 잘 만드는 삼전"
전부 다른 이름이지만, 결국 같은 회사를 의미한다. 이런 뉘앙스를 잡으려면 한국어 특화 임베딩 모델과 컨텍스트 데이터가 많이 필요함.
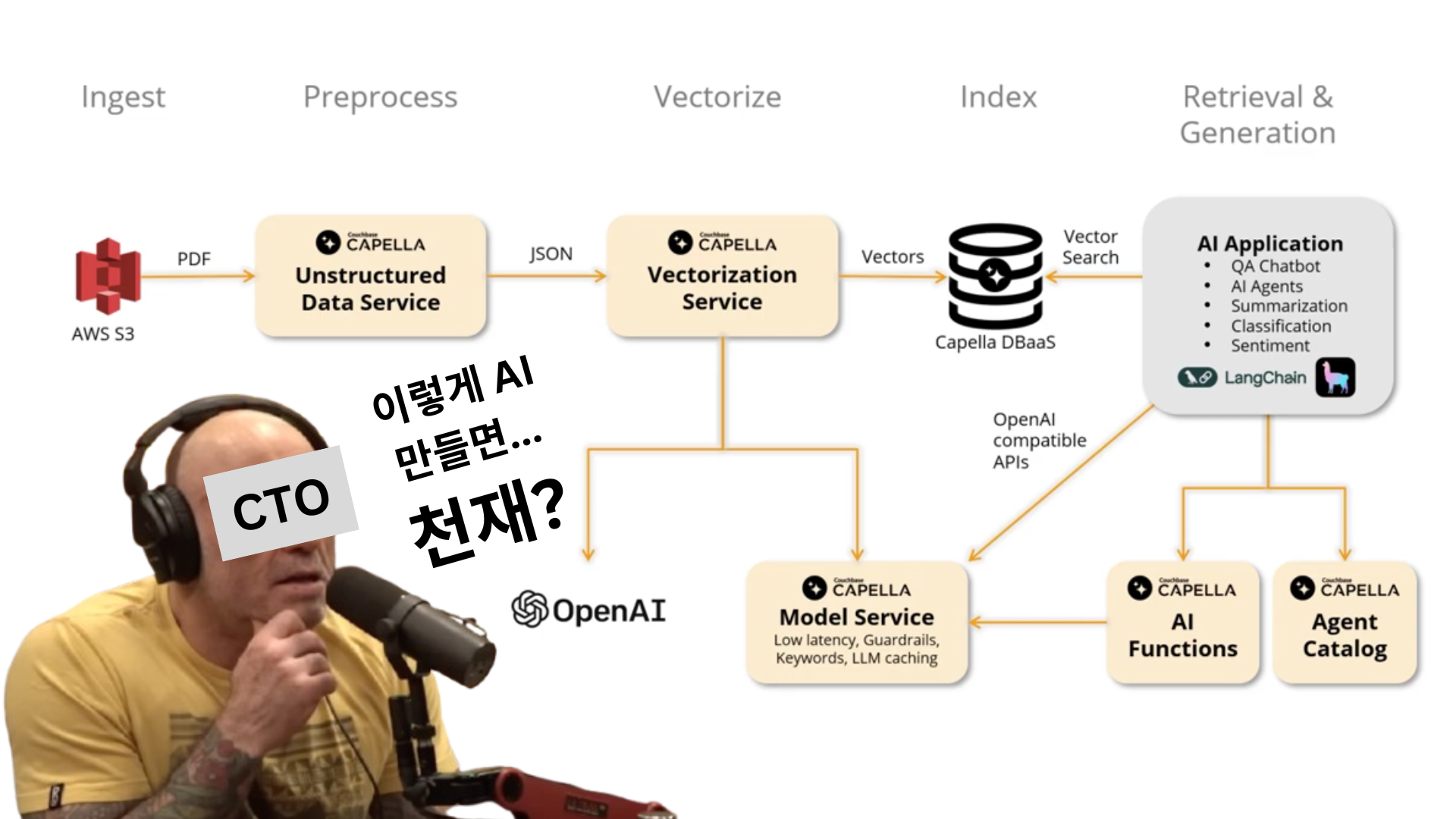
Couchbase의 JSON 네이티브 장점
단순한 질문 하나에도 언어학적 분석, 사용자 히스토리, 문화적 컨텍스트까지 다 저장해야 한다. 관계형 DB로 만들면 수십개 테이블로 쪼개질 수 있고, 관리 부담이 커진다. Couchbase는 이런 복잡한 구조를 하나의 문서로 자연스럽게 저장하고, 필요할 때 빠르게 조회할 수 있음.
한국어 특화 최적화 예시:
- 사용자별 언어 패턴 학습 데이터 저장
- 지역별 방언/슬랭 매핑 문서
- 시간대별 질문 경향 분석
- 개인화된 응답 스타일 캐싱
"어제 물어본 그거랑 비슷한 거 또 물어보네?" 이런 패턴까지 인식해서 더 자연스러운 대화를 만들 수 있음.
3. AI API 비용 절감하는 똑똑한 캐싱: "토큰도 돈인데..."
AI API 써본 사람은 안다. 토큰 비용이 만만치 않다는 걸. 아 다르고 어 다른게 한국어라서 동일 의미 길이 대비 토큰 수가 다소 더 나올 수 있어 실제 비용도 높아질 수 있다. 사용자들이 "BTS 멤버 이름 알려줘" 똑같은 질문을 하루에 100번 한다면?
똑똑한 캐싱 전략
일반적인 캐싱: "정확히 같은 질문"만 캐시 히트
- "BTS 멤버 이름 알려줘" ✓
- "BTS 멤버들 이름이 뭐야?" ✗ (캐시 미스)
Couchbase 벡터 검색 기반 캐싱:
의미가 비슷한 질문들을 벡터 유사도로 판별해서 캐시 히트율을 크게 높일 수 있다.
"BTS 멤버 이름", "방탄소년단 구성원", "BTS 일곱 명 이름" 전부 같은 답변 재활용.
계층적 캐싱 구조
Couchbase는 똑똑한 4단계 캐싱으로 응답 속도를 최적화한다.
1.먼저 정확히 같은 질문이 있었는지 확인하고,
2.없다면 벡터 검색으로 의미가 비슷한 질문의 답변을 찾는다.
3.그것도 없으면 관련 문서만 캐시에서 가져와서 LLM에게 새로 답변을 만들어달라고 요청하고,
4.정말 처음 보는 질문일 때만 처음부터 끝까지 AI API를 호출한다.
예시 분포를 보면:
- 1단계: 30% (완전 동일 질문)
- 2단계: 40% (의미 유사 질문)
- 3단계: 20% (관련 주제, 새로운 앵글)
- 4단계: 10% (완전 새로운 질문)
이렇게 하면 대부분의 질문을 매우 빠르게 처리할 수 있고, 토큰 비용도 크게 절약된다.
4. 개인정보보호법 대응: "데이터 한국에 두면 되는 거 아니야?"
한국 개인정보보호법은 까다롭다. 사용자 대화 내용, 검색 기록, 개인화 데이터를 해외 서버에 저장하면 문제가 될 수 있음. 외국 AI 회사가 한국 진출하려면 데이터 지역화(Data Localization)가 필수. 하지만 전 세계 서비스와 연동은 유지해야 하는 딜레마.
Couchbase 하이브리드 아키텍처:
- 한국 온프레미스: 사용자 개인정보, 대화 히스토리
- 글로벌 클라우드: 일반 지식 DB, 공개 문서
- 실시간 동기화: 개인정보 제외한 학습 데이터만 글로벌 공유
단순 연결이라면 동일한 Couchbase API로 온프레미스와 클라우드를 투명하게 연결할 수 있어서, 개발자는 데이터 위치를 크게 신경 쓸 필요 없음.
"데이터는 한국에, 성능은 전 세계 수준으로" 두 마리 토끼를 다 잡을 수 있다.
결국 엔지니어가 편해야 AI 서비스도 잘 돌아간다
ChatGPT 한국어 서비스를 만든다고 생각해보니, 결국 핵심은 "복잡함을 단순하게 만드는 것".

벡터 검색 + 문서 DB + 캐싱 + 실시간 분석... 이 모든 걸 따로따로 관리하다 보면 개발자는 비즈니스 로직보다 인프라 관리에 더 많은 시간을 쓰게 된다.
Couchbase가 제공하는 건 바로 이런 복잡성의 해결. JSON 네이티브니까 한국어 특화 데이터 구조를 자유롭게 설계할 수 있고, 벡터 검색이 내장되어 있어서 별도 시스템 연동 부담이 줄고, 하이브리드 배포로 규제 요구사항도 만족시킬 수 있다.
OpenAI든, 네이버든, 카카오든... 누가 한국형 AI를 만들던, 결국 기술적 우월성보다는 "사용자 경험"이 승부를 가를 것이다. 빠르고, 정확하고, 자연스러운 한국어 AI 서비스. 이런 걸 만들려면 결국 기반 기술부터 제대로 선택해야 한다.
성격 급한 한국 유저에게 "느려서 짜증난 적 없는" 그런 서비스ㅋㅋ
자세한 RAG 아키텍처나 한국어 AI 서비스 구축 전략이 궁금하면 언제든 메시지 주세요.



